注: 某些类名可能已更改(例如,RenderObject到LayoutObject,RenderLayer到PaintLayer)。
摘要
本文提供了在Chrome中实现硬件加速合成的背景和细节。
简介:为什么要进行硬件合成?
传统上,web浏览器完全依赖CPU来呈现网页内容。现在,即使是最小的设备,也有能力的gpu成为不可或缺的一部分,人们的注意力已经转向寻找更有效地使用这种底层硬件的方法,以实现更好的性能和节能。使用GPU合成网页的内容可以大大提高速度。
硬件合成的好处有三种:
- 在涉及大量像素的绘图和合成操作中,在GPU上合成页面层可以获得比CPU更好的效率(无论是在速度还是功耗方面)。硬件是专门为这些类型的工作负载设计的。
- GPU上已有的内容(如加速视频、Canvas2D或WebGL)不需要昂贵的回读。
- CPU与GPU之间的并行性,可以同时运行,创建高效的图形流水线。
最后,在我们开始之前,有一个很大的免责声明:Chrome图形堆栈在过去几年中已经有了实质性的发展。本文档将重点介绍编写时最先进的体系结构,这不是所有平台上的装运配置。有关在何处启用的功能的详细信息,请参阅GPU体系结构路线图。
第1部分:Blink渲染基础知识
Blink渲染引擎的源代码庞大、复杂,而且几乎没有文档记录。为了理解GPU加速在Chrome中的工作原理,首先了解Blink如何呈现页面的基本构建块是很重要的。
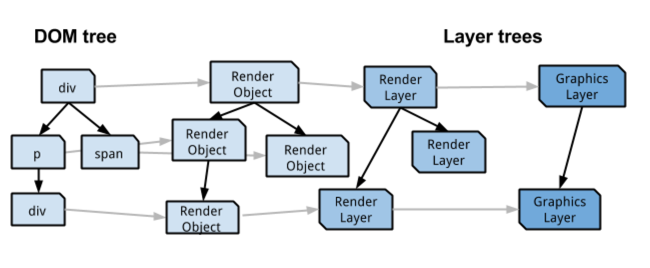
节点和DOM树
在Blink中,web页面的内容在内部存储为一个名为DOM树的节点对象树。页面上的每个HTML元素以及元素之间出现的文本都与一个节点相关联。DOM树的顶层节点始终是文档节点。
从节点到渲染对象
DOM树中产生可视输出的每个节点都有一个对应的RenderObject。RenderObjects存储在并行树结构中,称为渲染树。RenderObject知道如何在显示曲面上绘制节点的内容。它通过向GraphicsContext发出必要的draw调用来实现。GraphicsContext负责将像素写入位图,最终显示在屏幕上。在Chrome中,GraphicsContext包装了我们的2D绘图库Skia。
传统上,大多数GraphicsContext调用都变成了对SkCanvas或SkPlatformCanvas的调用,即立即绘制到软件位图中(有关Chrome如何使用Skia的旧模型的更多详细信息,请参阅本文档)。但是为了将绘画从主线移开(本文后面将详细介绍),这些命令现在被记录到一个SkPicture中。SkPicture是一种可串行化的数据结构,它可以捕获命令,然后在以后回放命令,类似于显示列表。
从渲染对象到渲染层
每个RenderObject都通过祖先RenderObject直接或间接地与RenderLayer关联。
共享相同坐标空间(例如受相同CSS变换影响)的渲染对象通常属于同一渲染层。RenderLayers存在,以便以正确的顺序合成页面元素,以正确显示重叠内容、半透明元素等。有许多条件将触发为特定RenderObject创建新的RenderLayer,如RenderBoxModelObject::RequireReslayer()中定义的,并覆盖某些派生类。RenderObject的常见情况,保证创建RenderLayer:
- 它是页面的根对象
- 它具有显式CSS位置属性(相对、绝对或转换)
- 它是透明的
- 具有溢出、alpha遮罩或反射
- 有CSS过滤器
- 对应于具有三维(WebGL)上下文或加速二维上下文的 canvas 元素
- 对应于 video 元素
注意,RenderObjects和RenderLayers之间没有一对一的对应关系。特定的RenderObject与为其创建的RenderLayer关联,如果有一个,或者与具有一个的第一个祖先的RenderLayer关联。
RenderLayers也构成树层次结构。根节点是与页面中根元素相对应的RenderLayer,每个节点的子节点都是可视化包含在父层中的层。每个渲染层的子层都被保存为两个排序列表,它们都按升序排序,其中NegzordList包含负z索引的子层(因此,位于当前层下的层)和PosZoorderList包含具有正z索引的子层(高于当前层的层)。
从渲染层到图形层
为了使用合成器,一些(但不是全部)渲染层会获得自己的背衬面(具有自己背衬面的层被广泛地称为合成层)。每个RenderLayer要么有自己的GraphicsLayer(如果是合成层),要么使用它的第一个祖先的GraphicsLayer。这类似于RenderObject与RenderLayers的关系。
每个GraphicsLayer都有一个GraphicsContext供相关的renderlayer绘制。在随后的合成过程中,合成器最终负责将GraphicsContexts的位图输出合并成最终的屏幕图像。
虽然理论上每个渲染层都可以将自己绘制到一个单独的背衬面中,但实际上这在内存方面可能是相当浪费的(尤其是VRAM)。在当前的Blink实现中,RenderLayer要获得自己的合成层,必须满足以下条件之一(请参见CompositingReasons.h):
- 层具有三维或透视变换CSS属性
- 层由使用加速视频解码的 video 元素使用
- 层由具有3D上下文或加速2D上下文的 canvas 元素使用
- 层用于合成插件
- 层使用CSS动画作为其不透明度,或使用动画webkit变换
- 层使用加速CSS过滤器
- 层的子体是合成层
- 层有一个具有较低z索引的同级,该同级有一个合成层(换句话说,该层与合成层重叠,应在其上渲染)
层压缩
没有规则就没有例外。如上所述,GraphicsLayer在内存和其他资源方面可能成本高昂(例如,一些关键操作的CPU时间复杂度与GraphicsLayer树的大小成正比)。可以为RenderLayer创建许多附加层,这些层将RenderLayer与其自己的背衬面重叠,这可能会非常昂贵。
我们称之为内在合成原因(例如,层上有三维变换)“直接”合成原因。当许多元素位于具有直接合成原因的层的顶部时,为了防止“层爆炸”,Blink使用多个与直接合成原因RenderLayer重叠的RenderLayer,并将它们“挤压”到单个备份存储中。这样可以防止重叠导致的层爆炸。更详细的激励层挤压可以在本演示中找到,更详细的代码之间的渲染层和合成层可以在本演示中找到;虽然该准则在2014年发生了重大变化,但截至2014年1月左右,这两个准则都是现行的。
从GraphicsLayers到WebLayers再到CC Layers
在我们开始Chrome的compositor实现之前,只需要再进行几层抽象!Graphicslayer可以通过一个或多个WebLayers来表示他们的内容。这些是WebKit端口需要实现的接口;请参阅Blink的public/platform目录以获取诸如WebContentsLayer.h或WebScrollbarLayer.h之类的接口。Chrome的实现在src/webkit/renderer/compositor\u绑定中,这些绑定使用Chrome compositor层类型实现抽象Web*层接口。
Putting it Together:合成
在概念上有四种并行树结构,它们的渲染目的略有不同:
- DOM树,这是我们的基本模型
- RenderObject树,它与DOM树的可见节点有1:1的映射。RenderObjects知道如何绘制相应的DOM节点。
- RenderLayer树,由映射到RenderObject树上RenderObject的RenderLayer组成。映射是多对一的,因为每个RenderObject要么与自己的RenderLayer关联,要么与拥有RenderLayer的第一个祖先的RenderLayer关联。RenderLayer树保留层之间的z顺序。
- GraphicsLayer树,将GraphicsLayer映射为一对多renderlayer。
每个GraphicsLayer都有用Chrome实现的WebLayers和Chrome合成层。合成器知道如何对这些最后的“cc层”(cc=Chrome合成器)进行操作。
从这里开始,在本文档中“layer”将指的是一个通用的cc层,因为对于硬件合成来说,这些是最有趣的——但是不要被愚弄了,在其他地方,当有人说“layer”时,他们可能指的是上面的任何构造!
现在我们(简短地)介绍了Blink中将DOM链接到合成器的数据结构,我们准备认真研究合成器本身。
第2部分:合成器
Chrome的compositor是一个用于管理GraphicsLayer树和协调框架生命周期的软件库。它的代码位于src/cc目录中,在Blink之外。
介绍合成器
回想一下,渲染分为两个阶段:首先绘制,然后合成。这允许合成器在每个合成层的基础上执行额外的工作。例如,合成器负责在合成每个合成层的位图之前,对其应用必要的变换(由层的CSS变换属性指定)。此外,由于层的绘制与合成分离,因此使这些层之一无效只会导致单独重新绘制该层的内容并重新组合。
每次浏览器需要创建一个新的框架时,合成器都会进行绘制。注意这个(令人困惑的)术语区别:
drawing是将层合并到最终屏幕图像中的合成器;
painting是图层背景的填充(带有软件光栅化的位图;硬件光栅化中的纹理)。
GPU在哪里?
那么GPU是如何发挥作用的呢?合成器可以使用GPU执行其drawing步骤。这与旧的软件渲染模型有很大的不同,在旧的软件渲染模型中,渲染器进程(通过IPC和共享内存)将带有页面内容的位图传递给浏览器进程进行显示(有关如何工作的更多信息,请参阅“附录F: 旧的软件渲染路径”附录)。
在硬件加速架构中,合成是通过调用特定于平台的3D api(Windows上的D3D;其他地方)。渲染器的合成器基本上是使用GPU将页面的矩形区域(即所有那些合成层,根据层树的变换层次相对于视口定位)绘制成单个位图,这是最终的页面图像。
架构插曲:GPU进程
在我们进一步研究合成器生成的GPU命令之前,了解渲染器进程如何向GPU发出任何命令非常重要。在Chrome的多进程模型中,我们有一个专门的进程来完成这个任务:GPU进程。GPU进程的存在主要是出于安全原因。请注意,Android是一个例外,Chrome使用进程内GPU实现,在浏览器进程中作为线程运行。另外,Android上的GPU线程的行为方式与其他平台上的GPU进程相同。
由于沙盒的限制,渲染器进程(包含Blink和cc的实例)不能直接调用OS(GL/D3D)提供的3D api。因此,我们使用一个单独的进程来访问设备。我们称这个进程为GPU进程。GPU进程是专门设计用来提供从渲染器沙盒或更严格的本地客户端“jail”中访问系统的3D api的。它通过客户机-服务器模型工作,如下所示:
- 客户机(在呈现程序中或NaCl模块中运行的代码)不是直接向系统api发出调用,而是将它们序列化并将它们放入一个环形缓冲区(命令缓冲区)中,该缓冲区位于自身和服务器进程之间共享的内存中。
- 服务器(在限制较少的沙盒中运行的GPU进程,允许访问平台的3D api)从共享内存中提取序列化命令,解析它们并执行适当的图形调用。
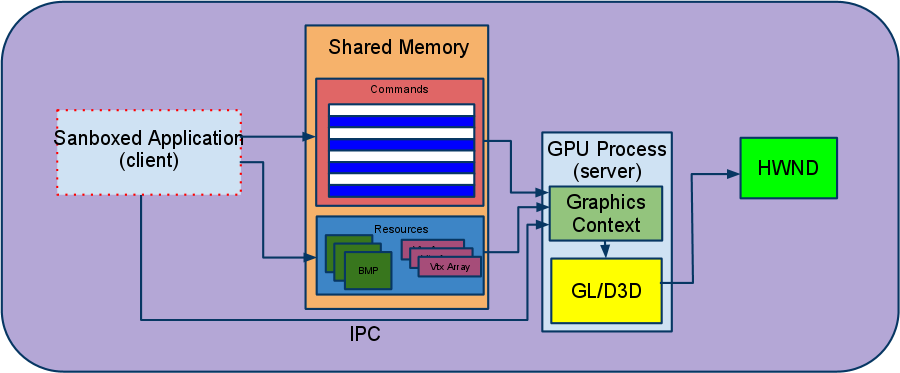
命令缓冲区
GPU进程接受的命令在GL ES 2.0API之后进行密切的模式化(例如,有一个与glClear、一个到GLDRAWARRARY等对应的命令)。由于大多数GL调用没有返回值,所以客户端和服务器可以以异步方式工作,从而使性能开销相当低。客户端和服务器之间的任何必要同步,例如客户端通知服务器需要执行其他工作,都通过IPC机制进行处理。
从客户机的角度来看,应用程序可以选择直接将命令写入命令缓冲区,或者通过我们提供的客户端库使用GL ES 2.0API,该库处理后台序列化。合成器和WebGL当前都使用GL ES客户端库以方便。在服务器端,通过命令缓冲区接收到的命令将转换为通过角度将调用转换为桌面OpenGL或Direct3D。
资源共享和同步
除了为命令缓冲区提供存储外,Chrome还使用共享内存在客户端和服务器之间传递更大的资源,例如纹理位图、顶点阵列等。有关命令格式和数据传输的详细信息,请参阅命令缓冲区文档。
另一个结构称为mailbox,提供了一种方法,可以在命令缓冲区之间共享纹理并管理它们的生命周期。mailbox是一个简单的字符串标识符,它可以附加(消耗)到任何命令缓冲区的本地纹理id,然后通过该纹理id别名访问。以这种方式附着的每个纹理id都会在底层真实纹理上保留一个参照,一旦通过删除局部纹理id释放所有参照,则真实纹理也将被销毁。
同步点用于在希望通过mailboxes共享纹理的命令缓冲区之间提供非阻塞同步。在命令缓冲区a上插入同步点,然后在命令缓冲区B上的同步点上“等待”,确保在B上插入的命令不会在插入同步点之前运行在a上的命令。
命令缓冲区多路复用
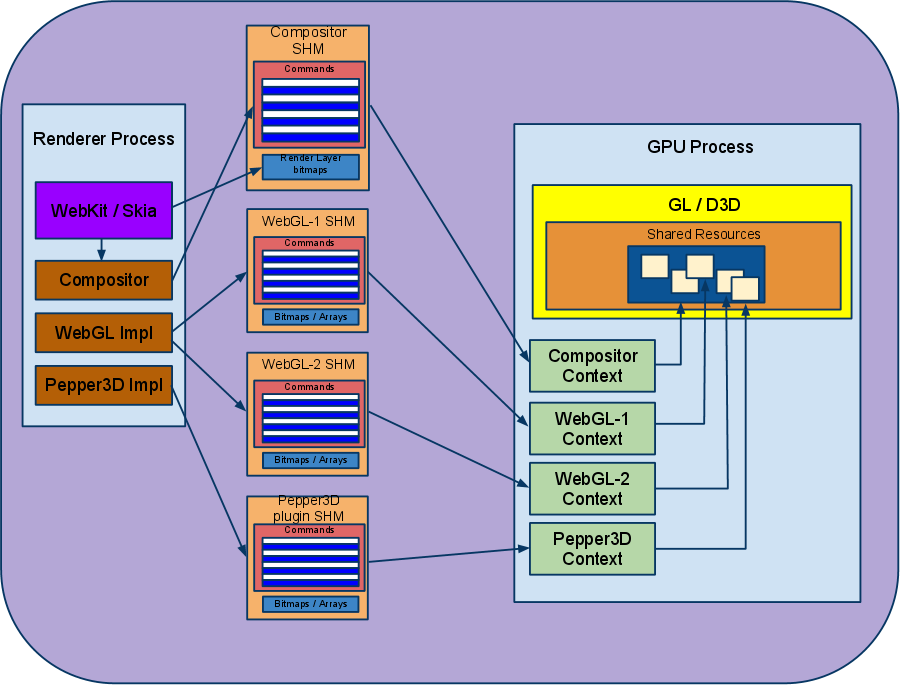
目前,Chrome对每个浏览器实例使用一个GPU进程,服务于所有渲染器进程和任何插件进程的请求。GPU进程可以在多个命令缓冲区之间进行多路复用,每个命令缓冲区都与自己的呈现上下文相关联。
每个渲染器可以有多个GL源,例如WebGL画布元素直接创建GL命令流。其内容直接在GPU上创建的层的合成工作如下:它们不是直接渲染到backbuffer中,而是渲染到纹理(使用帧缓冲区对象),合成器上下文在渲染GraphicsLayer时获取并使用该纹理。需要注意的是,为了使合成器的GL上下文能够访问由屏幕外GL上下文(即用于其他graphicslayer的fbo的GL上下文)生成的纹理,GPU进程使用的所有GL上下文都会被创建,以便它们共享资源。
生成的体系结构如下所示:
摘要
GPU进程体系结构提供了几个好处,包括:
- 安全性:大部分渲染逻辑仍保留在沙盒渲染器进程中,对平台3D api的访问仅限于GPU进程。
- 健壮性:GPU进程崩溃(例如,由于错误的驱动程序)不会导致浏览器关闭。
- 一致性:在opengles2.0上标准化作为浏览器的渲染API,不管平台是什么,都允许在Chrome的所有OS端口上使用一个更易于维护的代码库。
- 并行性:渲染器可以快速地将命令发布到命令缓冲区,并返回到CPU密集型的渲染活动,让GPU进程来处理它们。多亏了这个流水线,我们可以在多核机器上很好地利用这两个进程以及GPU和CPU。
有了这个解释,我们可以回到解释GL命令和资源是如何由渲染器的合成器生成的。
第3部分:线程合成器
合成器是在gles2.0客户端库之上实现的,该客户端库将图形调用代理到GPU进程(使用上面解释的方法)。当一个页面通过合成器呈现时,它的所有像素都被绘制出来(记住,绘制!=绘画)直接进入窗口的backbuffer通过GPU进程。
合成器的体系结构随着时间的推移而发展:最初它位于渲染器的主线程中,然后被移动到自己的线程(所谓的合成器线程),然后在绘制发生时承担额外的协调责任(所谓的impl-side绘制)。本文件将侧重于最新版本;请参阅GPU架构路线图,了解旧版本可能仍在使用的位置。
从理论上讲,线程合成器的基本任务是从主线程获取足够的信息,以独立地生成帧来响应未来的用户输入,即使主线程很忙并且不能请求额外的数据。实际上,这目前意味着它将为视口当前位置周围区域中的层区域制作cc层树和SkPicture记录的副本。
Recording:从Blink的角度绘画
感兴趣区域是在视口周围记录图片的区域。当DOM发生更改时(例如,由于某些元素的样式现在与前一个主线程框架不同并且已失效),Blink会将感兴趣区域内失效层的区域绘制到SkPicture-backed GraphicsContext中。这实际上并不产生新的像素,而是产生产生这些新像素所需的Skia命令的显示列表。此显示列表稍后将由合成器自行决定用于生成新像素。
commit:切换到合成器线程
线程合成器的关键属性是对主线程状态副本的操作,因此它可以生成帧,而无需向主线程请求任何内容。因此,线程合成器有两个面:主线程面和(名称不好的)“impl”面,这是合成器线程的一半。主线程有一个LayerTreeHost,它是层树的副本,impl线程有一个LayerTreeHostImpl,它是层树的副本。自始至终都遵循类似的命名约定。
从概念上讲,这两层树是完全独立的,合成器(impl)线程的副本可以用来生成帧,而不需要与主线程进行任何交互。这意味着主线程可以忙于运行JavaScript,而合成器仍然可以在GPU上重新绘制先前提交的内容,而不会中断。
为了产生新帧,合成器线程需要知道它应该如何修改它的状态(例如,更新层变换以响应滚动之类的事件)。因此,一些输入事件(如滚动)首先从浏览器进程转发到合成器,然后从合成器转发到渲染器主线程。通过控制输入和输出,线程合成器可以保证对用户输入的视觉响应。除了滚动之外,合成器还可以执行任何其他页面更新,而不需要请求Blink重新绘制任何内容。到目前为止,CSS动画和CSS过滤器是其他主要的合成器驱动的页面更新。
两层树由一系列称为commit的消息保持同步,这些消息由合成器的调度程序(在cc/trees/thread\u proxy.cc中)介导。commit将主线程的世界状态传输到合成器线程(包括更新的层树、任何新的SkPicture记录等),阻塞主线程以便可以进行此同步。它是主线程参与特定帧的生产的最后一步。
在自己的线程中运行合成器允许合成器的层树副本在不涉及主线程的情况下更新层转换层次结构,但是主线程最终也需要滚动偏移信息(例如,JavaScript可以知道视口滚动到的位置)。因此,commit还负责将任何合成器线程层树更新应用于主线程的树和一些其他任务。
有趣的是,这种体系结构是JavaScript touch事件处理程序阻止合成滚动的原因,而滚动事件处理程序却没有。JavaScript可以在touch事件上调用preventDefault(),但不能在scroll事件上调用。因此,如果合成器不首先询问JavaScript(在主线程上运行)是否要取消传入的touch事件,就无法滚动页面。另一方面,滚动事件是无法阻止的,并且是异步传递给JavaScript的;因此,无论主线程是否立即处理滚动事件,合成器线程都可以立即开始滚动。
树激活
当合成器线程从主线程获得一个新的图层树时,它会检查新的树以查看哪些区域无效,并重新光栅化这些图层。在此期间,活动树仍然是合成器线程以前的旧层树,挂起树是内容正在光栅化的新层树。
为保持显示内容的一致性,只有当其可见(即在视口中)高分辨率内容完全光栅化时,挂起树才会激活。从当前活动树交换到现在准备就绪的挂起树称为激活。等待光栅化内容就绪的净效果意味着用户通常至少可以看到一些内容,但这些内容可能已经过时。如果没有可用的内容,Chrome将显示一个空白或棋盘格图案,而使用GL着色器。
需要注意的是,即使是活动树的光栅区域也可以滚动过去,因为Chrome只记录感兴趣区域内的图层区域的SkPictures。如果用户滚动到一个未记录的区域,合成器将要求主线程记录和提交额外的内容,但是如果不能记录、提交和光栅化新内容以及时激活,用户将滚动到棋盘区域。
为了减少棋盘格,Chrome还可以在高分辨率之前快速为挂起的树光栅化低分辨率内容。如果只有低分辨率内容可用于视口的挂起树比当前屏幕上的内容更好(例如,传出的活动树对于当前视口根本没有光栅化内容),则会激活该树。tile管理器(将在下一节中介绍)决定何时光栅化哪些内容。
此体系结构将光栅化与帧生产流的其余部分隔离开来。它支持多种技术来提高图形系统的响应能力。图像解码和调整大小操作是异步执行的,这是以前在绘制期间执行的昂贵的主线程操作。本文前面提到的异步纹理上传系统也与impl side painting一起介绍。
平铺
将页面上的每个层的整个光栅化是浪费CPU时间(用于绘制操作)和内存(RAM用于任何软件位图,该层需要;纹理存储的VRAM)。合成器不必对整个页面进行光栅化,而是将大多数web内容层拆分为平铺,并在每个平铺基础上对层进行栅格化。
Web内容层平铺的优先级由许多因素启发式地排序,包括该平铺与视口的接近程度及其在屏幕上的估计时间。然后,GPU内存根据其优先级分配给瓷砖,并从SkPicture录制中擦除瓷砖,以按优先级顺序填充可用内存预算。目前(2014年5月)正在重新加工瓷砖优先级的具体方法;有关详细信息,请参阅“瓷砖优先级设计文档”。
注意,对于内容已经驻留在GPU上的图层类型(例如加速视频或WebGL),不需要平铺(对于好奇的情况,图层类型是在cc/layers目录中实现的)。
光栅化:从cc/Skia的角度看绘画
合成线程上的SkPicture记录可以通过两种方式之一转换为GPU上的位图:由Skia的软件光栅化器绘制成位图并作为纹理上传到GPU,或者由Skia的OpenGL后端(Ganesh)直接绘制到GPU上的纹理。
对于Ganesh光栅化层,SkPicture将与Ganesh一起播放,并通过命令缓冲区将生成的GL命令流传递给GPU进程。当合成器决定对任何瓷砖进行光栅化时,GL命令生成立即发生,并且将瓷砖捆绑在一起,以避免在GPU上进行平铺光栅化的开销。有关该方法的更多信息,请参阅GPU加速光栅化设计文档。
对于软件光栅化层,绘制目标是渲染器进程和GPU进程之间共享的内存中的位图。位图通过上述资源传输机制传递给GPU过程。由于软件光栅化可能非常昂贵,所以这种光栅化不会发生在compositor线程本身(在其中它可以阻止为活动树绘制新框架),而是在compositor光栅工作线程中。多光栅工作线程可以用来加速软件光栅化;每个工作人员都从优先级的平铺队列前面提取。已完成的瓷砖将作为纹理上载到GPU。
位图纹理上传是内存带宽受限平台上的一个不平凡的瓶颈。这妨碍了软件光栅化层的性能,并继续妨碍硬件光栅化器所需位图的上传(例如,对于图像数据或CPU渲染的掩码)。Chrome过去有各种不同的纹理上传机制,但最成功的是一个异步上传器,它在GPU进程的工作线程中执行上传(或者在浏览器进程中的附加线程,在Android的情况下)。这就防止了其他操作不得不阻止可能长时间的纹理上载。
一种完全消除纹理上传问题的方法是在暴露此类原语的统一内存体系结构设备上使用CPU和GPU共享的零拷贝缓冲区。Chrome目前不使用此结构,但将来可能使用;有关详细信息,请参阅GpuMemoryBuffer设计文档。
另外,在使用GPU进行光栅化时,还可以采取第三种方法来绘制内容:在绘制时将每个层的内容直接光栅化到backbuffer中,而不是事先将其绘制为纹理。这具有节省内存(无中间纹理)和一些性能改进(在绘图时将纹理副本保存到backbuffer)的优点,但当纹理有效缓存层内容时(因为现在需要重新绘制每个帧)时,性能会降低。“直接到backbuffer”或“direct Ganesh”模式在2014年5月之前未实现,但有关其他相关考虑,请参阅GPU光栅化设计文件。
在GPU、平铺和四边形上绘制
一旦填充了所有的纹理,呈现页面的内容就只需对层层次结构进行深度优先遍历,然后发出GL命令,将每个层的纹理绘制到帧缓冲区中。
在屏幕上绘制一个图层实际上就是绘制它的每个瓷砖。瓷砖表示为四边形(简单的4角,即矩形;请参见用给定层内容的子区域填充绘制的cc/quads。合成器生成四边形和一组渲染过程(渲染过程是包含四边形列表的简单数据结构)。用于绘制的实际GL命令是与四边形分开生成的(请参见cc/output/GL\u renderer.cc)。这是从quad实现中抽象出来的,因此可以为合成器编写非GL后端(唯一重要的非GL实现是软件合成器,稍后将介绍)。绘制四边形大致相当于为每个渲染过程设置视口,然后在渲染过程的四边形列表中为每个四边形设置变换并绘制。
请注意,首先执行遍历深度可确保cc层的正确z顺序,并且与该cc层关联的潜在多个RenderLayers的z顺序在绘制层的RenderObjects时通过RenderObjectTree遍历的顺序提前得到保证。
可变比例因子
impl-side painting的一个显著优点是合成器可以以任意比例因子重新呈现现有的SkPictures。这在两种主要情况下非常有用:收缩到缩放和在快速翻转期间生成低分辨率的平铺。
合成器将截获用于收缩/缩放的输入事件,并在GPU上适当缩放已光栅化的分幅,但在发生这种情况时,它也会以更合适的目标分辨率重新启动。每当新的磁贴准备就绪(光栅化和上传)时,可以通过激活挂起的树来交换它们,从而提高收缩/缩放屏幕的分辨率(即使收缩尚未完成)。
在软件中进行光栅化时,合成器还尝试快速生成低分辨率的瓷砖(通常绘制成本要低得多),如果高分辨率瓷砖还没有准备好,则在滚动过程中显示它们。这就是为什么有些页面在快速滚动时看起来很模糊的原因——合成器在屏幕上显示低分辨率的平铺,而高分辨率的平铺是光栅。
附录A:浏览器合成
本文档主要介绍用于显示web内容的呈现程序过程中的活动。不过,Chrome的UI也使用了相同的底层合成基础设施,值得注意的是浏览器的参与。
浏览器合成 Aura/Ash
Chrome&ChromeOS有一个由Ash和Aura组合而成的复合窗口管理器(Ash是窗口管理器本身,而Aura提供了窗口和输入事件等基本原语)。窗口管理器Ash只在ChromeOS和Win8的Metro模式下使用;在Linux和非Metro Windows上,Aura Windows包装本机操作系统Windows。Aura使用cc来合成Aura窗口,而Views使用cc-through-Aura来合成窗口浏览器UI中的不同元素。大多数光环窗口只有一层,尽管有些视图也可以弹出到自己的层中。这些镜像了Blink使用cc合成web内容层的方式。有关Aura的更多信息,请参阅Aura设计文档索引。
Übercompositor
最初,Blink会将渲染器的所有层(即web内容区域的层)合成为一个纹理,然后该纹理将通过浏览器进程中cc的第二个副本与浏览器UI的其余层合成。这很简单,但有一个主要的缺点,那就是在每一帧中都会产生一个额外的视口大小副本(因为内容层首先被合成为一个纹理,然后在浏览器合成器的绘制过程中该纹理会被复制)。
这个Übercompositor在一个绘图过程中执行浏览器UI和渲染器层的所有合成。渲染器不是自己绘制四边形,而是将所有四边形都交给浏览器,在浏览器合成器的层树中,它们被绘制在DelegatedRenderLayer的位置。有关此主题的更多详细信息,请参阅üBER合成器设计文件。
附录B:软件合成器
在某些情况下,硬件合成是不可行的,例如,如果设备的图形驱动程序被封锁,或者设备完全没有GPU。对于这些情况,是GL渲染器的替代实现,称为softwarerender(参见src/cc/output/software\u renderer)。当OutputSurface(参见src/cc/output/output\u surface)ContextProvider不可用时,许多其他地方(RasterWorkerPool、ResourceProvider等)也需要自己的软件回退。总而言之,在不使用GPU的情况下运行时,Chrome在软件方面的功能大致相同,但在实现上有一些关键的区别:
- 它没有将四边形作为纹理上传到GPU,而是将它们留在系统内存中,并作为共享内存来回穿梭
- 软件渲染器没有使用GL将内容纹理分片复制到backbuffer中,而是使用Skia的软件光栅化器来执行复制(并执行任何必要的矩阵运算和剪裁)
这意味着像3D转换和复合CSS过滤器这样的操作“只适用于”软件渲染器,但本质上依赖GL(例如WebGL)的web内容却不适用。对于WebGL的软件渲染,Chrome使用SwiftShader,一个软件GL光栅化器。
附录C:Grafix 4 N00bs词汇表
bitmap:内存中像素值的缓冲区(主存储器或GPU的视频RAM)
texture:一个位图,用于GPU上的三维模型 —— 纹理
texture quad:应用于非常简单模型的纹理:四点多边形,例如矩形。当您只想将纹理显示为平面矩形曲面时非常有用,可能会转换(二维或三维),这正是我们在合成时所做的。
invalidation:标记为脏的文档区域,通常意味着需要重新打印。样式系统有一个类似的无效概念,因此样式也可以被玷污,但通常这指的是需要重新绘制的区域。
painting:在我们的术语中,渲染阶段,RenderObjects调用GraphicsContext API以使自己可视化表示
rasterization:在我们的术语中,渲染的阶段,位图备份渲染层是填充的。这可能会立即发生,因为GraphicsContext调用是由RenderObjects进行的,或者如果我们使用SkPicture记录进行绘制和SkPicture回放进行光栅化,则可能在稍后发生。
compositing:按照我们的说法,渲染阶段,将RenderLayer的纹理合并为最终屏幕图像
drawing:在我们的术语中,渲染的阶段,实际上把像素放在屏幕上(即将最终的屏幕图像放到屏幕上)。
backbuffer:当双缓冲时,呈现到的屏幕缓冲区,而不是当前显示的缓冲区
frontbuffer:当双缓冲时,当前显示的屏幕缓冲区,而不是当前呈现到的屏幕缓冲区
swapbuffers:切换前缓冲区和后缓冲区
Frame Buffer Object:OpenGL术语,用于纹理,可以渲染到屏幕外,就像它是一个普通屏幕缓冲区(例如backbuffer)。对我们很有用,因为我们希望能够渲染到纹理,然后复合这些纹理;有了FBO,我们可以假装给WebGL自己的框架,它不必担心页面上发生的任何其他事情。
damage:屏幕的区域,它被用户交互或编程更改(例如JavaScript更改样式)“污染”。这是更新时需要重新绘制的屏幕区域。
retained mode:图形系统维护要渲染对象的完整模型的渲染方法。web平台保留在DOM是模型的状态,平台(即浏览器)跟踪DOM的状态,其API(即JavaScript对DOM的访问)可以用于修改或查询其当前状态,但浏览器可以随时从模型呈现,而不需要JavaScript的任何指令。
immediate mode:一种渲染方法,图形系统不跟踪整个场景状态,而是立即执行给它的任何命令,并忘记它们。要重新绘制整个场景,需要重新发出所有命令。Direct3D是即时模式,就像Canvas2D一样。
context virtualization(上下文虚拟化):GPU进程不一定为给定的命令缓冲区客户端创建实际的驱动程序级GL上下文。它还可以为多个客户端提供共享的真实上下文,并在解析其GL命令时将GL状态恢复到给定客户端的预期状态——我们将此阴影状态称为“虚拟上下文”。这在Android上用于解决某些驱动程序的错误和性能问题(GL上下文切换慢、FBO跨多上下文呈现的同步问题以及使用共享组时崩溃)。Chrome通过GPU阻止列表文件在驱动程序子集上启用上下文虚拟化。
附录D:相关标志
如果您对合成层的结构感兴趣,请使用“显示合成层边界”标志。您也可以尝试“线程合成”、“线程动画”。全部提供about:flags.
如前所述,WebKit(和Chromium)中的加速合成只有在某些类型的内容出现在页面上时才起作用。强制页面切换到合成器的一个简单技巧是提供一个-webkit-transform:translateZ(0)页中的元素。
附录E:调试合成层
使用–show composited layer borders标志将显示图层周围的边框,并使用颜色显示有关图层或图层中的平铺的信息。
这些颜色有时会发生变化,以前的列表很快就会过时,因此请参阅src/cc/debug/debug\u colors.cc中的注释以了解当前的颜色列表及其含义。
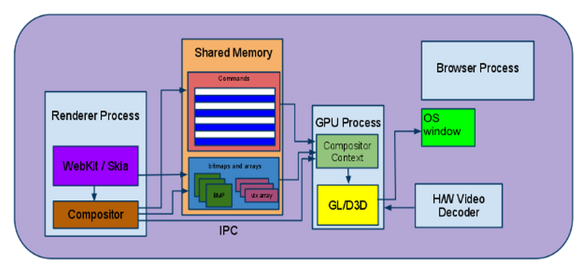
附录F:旧的软件渲染路径
本节将作为WebKit预合成的原始设计的一部分,供后人参考。这条路到2014年5月仍在徘徊,但很快将彻底被移除。
WebKit从根层开始遍历RenderLayer层次结构,从根本上呈现网页。WebKit代码库包含两个不同的代码路径,用于呈现页面内容,软件路径和硬件加速路径。软件路径是传统的模型。
在软件路径中,通过从后到前依次绘制所有渲染层来渲染页面。RenderLayer层次结构从根开始递归遍历,大部分工作都在RenderLayer::paintLayer()中完成,该过程执行以下基本步骤(此处简化步骤列表以明确):
确定层是否与早期输出的损坏矩形相交。
递归地为NegzordList中的层调用paintLayer()来绘制此层下面的层。
要求与此渲染层关联的渲染对象绘制自己。
这是通过递归的RenderObject树从创建层的RenderObject开始的。每当发现与不同渲染层关联的RenderObject时,遍历停止。
通过调用posZOrderList中的图层的paintLayer()递归地绘制此层之上的层。
在这种模式下,RenderObjects通过向单个共享GraphicsContext发出绘制调用(通过Skia在Chrome中实现)来将自己绘制到目标位图中。
注意GraphicsContext本身没有图层概念,但是为了使半透明图层的绘制正确,在要求渲染对象绘制之前,有一个警告:半透明RenderLayers调用GraphicsContext::BeginSparkyLayer()。在Skia实现中,对begin途SparkyLayer()的调用会导致所有后续的绘制调用以单独的位图呈现,当图层图形完成时,将与原始图形合成,并在绘制所有半透明RenderLayer的RenderLabel项目后,对GraphicsContext调用endTransparencyLayer()进行匹配调用。
From WebKit to the Screen
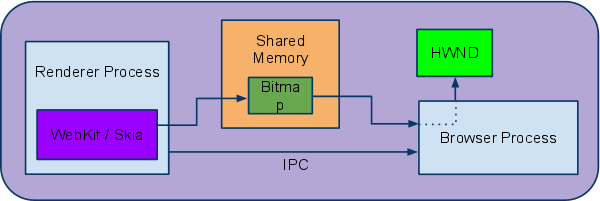
一旦所有渲染层都绘制到共享位图中,位图仍然需要在屏幕上显示。在Chrome中,位图驻留在共享内存中,位图的控制权通过IPC传递给浏览器进程。然后,浏览器进程负责通过操作系统的窗口API(例如,使用Windows上的相关HWND)在适当的选项卡/窗口中绘制位图。